
مرحبا بكم فى كبسولات الحوسبة السحابية من ألف محترف سحابي حيث نقدم مقدمة مبسطة للخدمات الرئيسية لأيه دبليو اس (AWS).
لماذا هذه الكبسولات؟
سوف تساعدك هذه الكبسولات من “ألف محترف حوسبي” على التعرف على العديد من الخدمات و المكونات السحابية المقدمة من AWS.
نقدم لكم فى هذه الكبسولة السحابية منهجية اختيار قاعدة البيانات المتجهية (Vector Store) على AWS: دليل عملي لاتخاذ القرار و هو ما سوف يساعد مهندسي البرمجيات والمعماريين فى بناء تطبيقات RAG (Retrieval-Augmented Generation) على AWS.
في التطبيقات الحديثة خصوصًا تلك التي تعتمد على الذكاء الاصطناعي التوليدي لم يعد اختيار قاعدة بيانات واحدة كافيًا.
تقليديًا، كان القرار يدور بين:
- قواعد البيانات العلائقية (RDS) للبيانات المنظمة والمعاملات (ACID)
- قواعد NoSQL (مثل DynamoDB) للمرونة والتوسع
حديثا ظهر نمط ثالث و هو:
- قواعد البيانات المتجهية (Vector Databases) للبحث الدلالي (Semantic Search)
وهذا يعني أن النظام لم يعد يعتمد على نموذج بيانات واحد، بل أصبح يمزج بين عدة أنماط حسب الحاجة.
السؤال العملي هنا:
إذا كنت تحتاج إلى Vector Store على AWS، هل تختار
OpenSearch (k-NN) أم Aurora PostgreSQL مع pgvector؟
نظرة سريعة: كيف تفكر في القرار؟
يوضح الشكل التالي إطارًا مبسطًا لاتخاذ القرار:
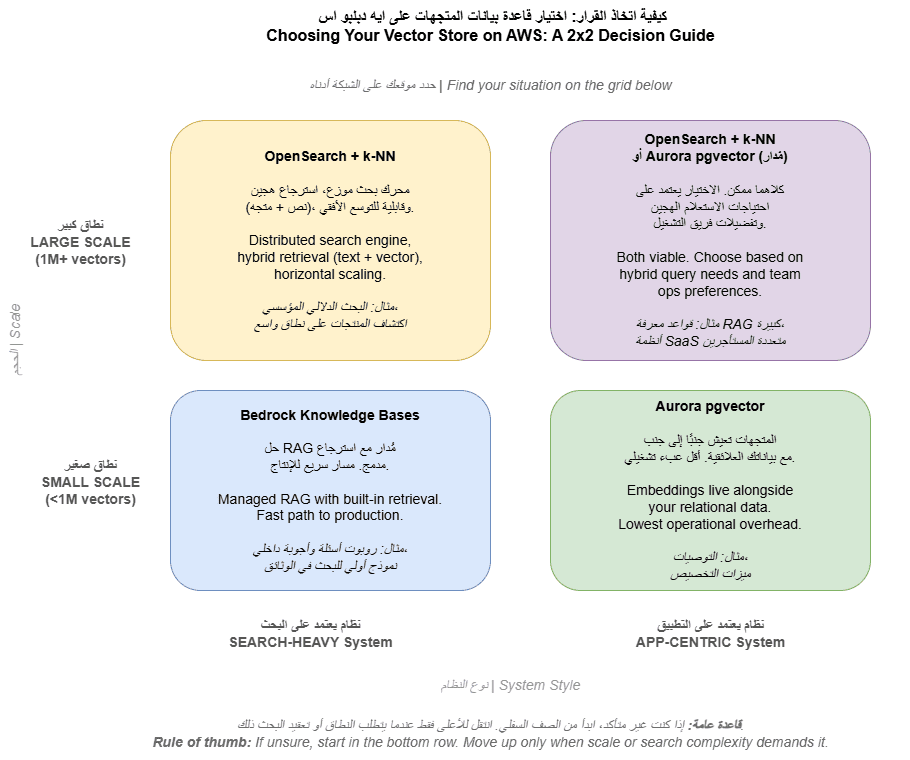
- هل النظام Search-heavy أم Application-centric؟
- ما هو حجم البيانات (عدد الـ vectors)؟
القاعدة العامة:
ابدأ بالحل الأبسط، وانتقل للحلول الأكثر تعقيدًا فقط عند الحاجة.
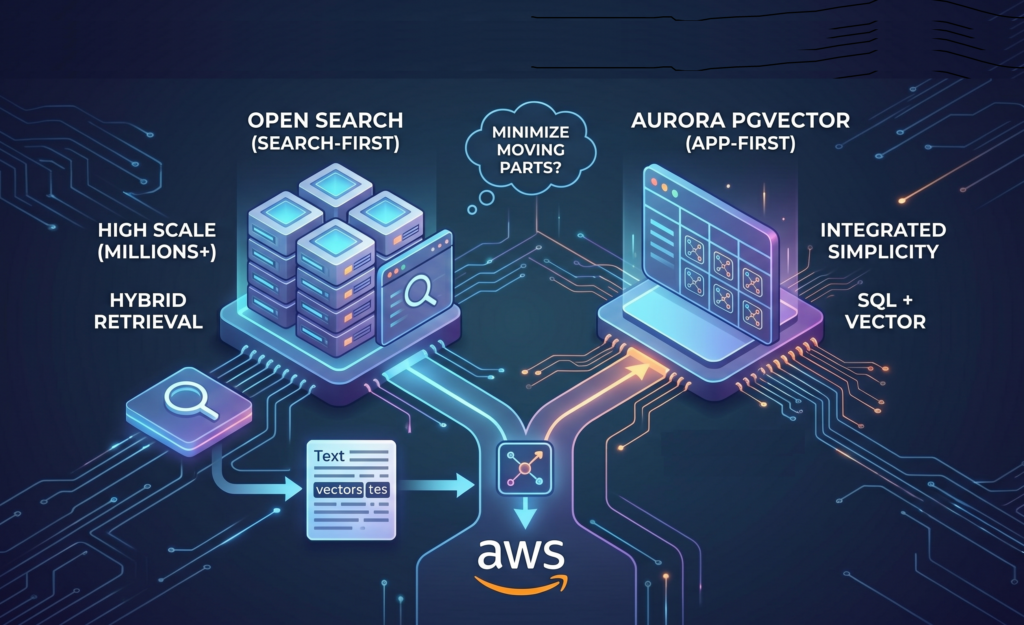
OpenSearch مع k-NN: نهج “Search-First”
تدعم خدمة Amazon OpenSearch البحث المتجهي باستخدام k-Nearest Neighbors (k-NN).
تعتمد داخليًا على خوارزميات Approximate Nearest Neighbor مثل HNSW لتحقيق توازن بين السرعة والدقة.
الخصائص الرئيسية:
- مصممة للأنظمة التي يكون فيها البحث عنصرًا أساسيًا
- تدعم البحث الهجين (نصي + متجهي)
- قابلة للتوسع أفقيًا (horizontal scaling)
متى تختار OpenSearch؟
- عندما تحتاج إلى Hybrid Retrieval (بحث نصي + دلالي)
- عندما يكون لديك ملايين الـ vectors أو أكثر
- عندما يكون البحث جزءًا أساسيًا من النظام (Core Capability)
- إذا كنت تستخدم بالفعل طبقة Search في النظام
الفكرة الذهنية:
OpenSearch يتعامل مع المعنى كما تتعامل محركات البحث التقليدية مع الكلمات.
Aurora PostgreSQL + pgvector: نهج “Application-First”
تدعم Aurora PostgreSQL البحث المتجهي عبر إضافة pgvector، مما يسمح بتخزين الـ embeddings داخل نفس قاعدة البيانات.
الخصائص الرئيسية:
- تخزين الـ embeddings داخل جداول PostgreSQL العادية
- دعم عمليات similarity search باستخدام معاملات مثل
<=> - الجمع بين SQL filtering + vector similarity
مثال بسيط:
SELECT id, name, price
FROM products
WHERE price < 100
ORDER BY description_embedding <=> '[0.12, 0.34, ...]'::vector
LIMIT 5;
متى تختار pgvector؟
- عندما تريد نظامًا واحدًا بدلًا من نظامين
- عندما يكون حجم البيانات متوسط
- عندما تحتاج إلى ربط قوي بين بيانات التطبيق والـ embeddings
- إذا كان فريقك يعمل بالفعل على PostgreSQL
خلاصة الفكرة:
pgvector مناسب عندما يكون البحث المتجهي “ميزة داخل التطبيق”، وليس نظامًا قائمًا بذاته.
مقارنة سريعة (Decision Matrix)
| العامل | OpenSearch (k-NN) | Aurora pgvector |
|---|---|---|
| نمط المعمارية | Search-first | Application-first |
| التوسع | عالي (ملايين+) | متوسط |
| نوع الاستعلام | Hybrid (نصي + متجهي) | SQL + Vector |
| التعقيد التشغيلي | أعلى | أقل |
| نموذج النشر | Cluster مستقل | داخل قاعدة البيانات |
| أفضل استخدام | أنظمة بحث كثيفة | أنظمة تطبيقية |
التكلفة (نظرة عامة)
تختلف التكلفة حسب الحجم، لكن يمكن التفكير فيها بهذا الشكل:
- أحجام صغيرة (آلاف إلى عشرات الآلاف):
- pgvector غالبًا أوفر لأنه يعمل داخل قاعدة بيانات موجودة
- أحجام كبيرة (ملايين):
- OpenSearch يصبح أكثر كفاءة بفضل التوزيع الأفقي
- OpenSearch يحتاج عادةً إلى عدة nodes
- pgvector يبدأ بالتوسع رأسيًا (vertical scaling)
ملاحظة:
أسعار AWS تتغير باستمرار—الأهم هو فهم شكل التكلفة وليس الأرقام الدقيقة.
مثال عملي: نفس الاستعلام بطريقتين
باستخدام pgvector
SELECT id, name, price
FROM products
WHERE price < 100
ORDER BY description_embedding <=> '[0.12, 0.34, ...]'::vector
LIMIT 5;
باستخدام OpenSearch
{
"size": 5,
"query": {
"bool": {
"filter": [
{ "range": { "price": { "lt": 100 } } }
],
"must": [
{
"knn": {
"description_embedding": {
"vector": [0.12, 0.34, ...],
"k": 5
}
}
}
]
}
}
}
الفرق الحقيقي:
- مع pgvector: التعقيد داخل قاعدة البيانات
- مع OpenSearch: التعقيد في طبقة البحث المنفصلة
أين يأتي دور Amazon Bedrock؟
تقدم Amazon Bedrock نماذج ذكاء اصطناعي جاهزة للاستخدام (Foundation Models).
في معمارية RAG:
- المستخدم يرسل الاستعلام
- يتم جلب السياق من الـ vector store
- يتم تمرير السياق للنموذج
- يتم توليد الإجابة
نقطة مهمة:
Bedrock مسؤول عن التوليد (Generation)
وليس عن تخزين البيانات
ماذا عن Bedrock Knowledge Bases؟
تقدم:
- توليد embeddings
- Retrieval جاهز
- تكامل مع vector stores
لكن لها trade-offs:
- تحكم أقل في تفاصيل retrieval
- مرونة أقل عند التوسع
- تكلفة إضافية لكل استعلام
متى لا تستخدم Vector Database؟
ليست كل مشكلة تحتاج Vector Search.
تجنب استخدامها عندما:
- تحتاج ACID transactions صارمة → استخدم RDS
- تحتاج استعلامات بسيطة key-value → استخدم DynamoDB
- تحتاج نتائج دقيقة تمامًا (deterministic)
مثال:
نظام مدفوعات لا يجب أن يعتمد على similarity—بل على نتائج دقيقة 100%.
الخلاصة (Final Verdict)
لا يوجد حل واحد مناسب للجميع … الأمر يعتمد على السياق.
اختر OpenSearch عندما:
- البحث عنصر أساسي في النظام
- تحتاج hybrid retrieval
- لديك حجم بيانات كبير
اختر pgvector عندما:
- تريد البساطة
- البحث المتجهي جزء من التطبيق
- تستخدم PostgreSQL بالفعل
اختر Bedrock Knowledge Bases عندما:
- تريد حلًا مُدارًا سريعًا للانطلاق
أفكار ختامية
أفضل Vector Store ليس مجرد مقارنة ميزات—
بل هو قرار حول أين تعيش التعقيدات في نظامك.
- إذا كان نظامك يعتمد على البحث قم باختيار OpenSearch
- إذا كان يعتمد على التطبيق قم باختيار pgvector
- إذا كنت تريد سرعة التنفيذ قم باختيار Bedrock KB
ختاما: الأنظمة الحديثة لا تختار قاعدة بيانات واحدة بل تجمع بين عدة أنماط بطريقة عملية وقابلة للتوسع.
اذا اعجبكتم هذه الكبسولة السحابية فسارعوا بالاشتراك فى قائمة ألف محترف حوسبي البريدية ليصلكم كل جديد – نقوم بنشر كبسولة جديدة كل فترة قصيرة على أمل أن نساعدكم فى تطوير مهاراتكم التقنية.
كذلك تابعونا على منصات التواصل الاجتماعى لتصلكم عروضنا الجديدة و كوبونات توفير ألف محترف سحابي.